Data engineers deserve better code review
Know Your dbt Data Quality Score
Data Quality Score
See where you stand in 10 seconds.
Free 90-day beta · 60 second setup
Data Engineers Deserve Better Code Review
Schema Changes Break Silently
Column renames break downstream models. Dashboards show wrong data for weeks. Nobody notices until the CFO asks questions.
Manual Review Misses Things
10+ hours/week reviewing PRs. Junior engineers ship bugs. Senior engineers are overwhelmed and can't check everything.
Generic Tools Don't Understand dbt
CodeRabbit treats SQL like Python. Misses {{ ref() }} dependencies. Doesn't understand incremental models or schema.yml.
Why Teams Trust StackSherpa
Built on 13,186 real dbt columns from thousands of production projects.
Stuck at <20% test coverage? You're not alone.
Most dbt teams know they should test more but just don't know where to start. We show you what to add, and explain why it matters.
Patterns from Real Teams
We analyzed thousands of dbt repos (8,355 models) to learn what works.
We've seen
block_timestamp in 611 repos.When you write
amount, we've seen that pattern in 75 repos. You get the same recommendations they trust.
See Your Score Instantly sec
Open a PR. Get your Trust Score instantly. Works immediately.
Your score goes from 33 → 465.
We can analyze 16 files, 456 columns while you grab your coffee.
Ship Your First Test min
Copy. Paste. Commit. Your first test is live in 5 minutes.
Primary keys? Add
unique + not_nullForeign keys? Add
relationships testWe tell you the right tests for each column type, based on your model's layer (staging, fact, mart, etc.).
Built For Growing dbt Teams
Under 20% Test Coverage
Testing feels like guesswork. We give you a clear roadmap based on what actually works in thousands of real dbt projects.
Waste Hours on Manual PR Reviews
Your senior engineers are bottlenecked reviewing PRs. Your junior engineers don't know what to test. We automate the obvious stuff.
Need Enterprise Quality Without Enterprise Overhead
Small enough to move fast (3-15 engineers), big enough to need process. No complex setup, no vendor calls.
See Your Trust Score Transform
Real analysis. Real speed. Real PR from a production dbt project.
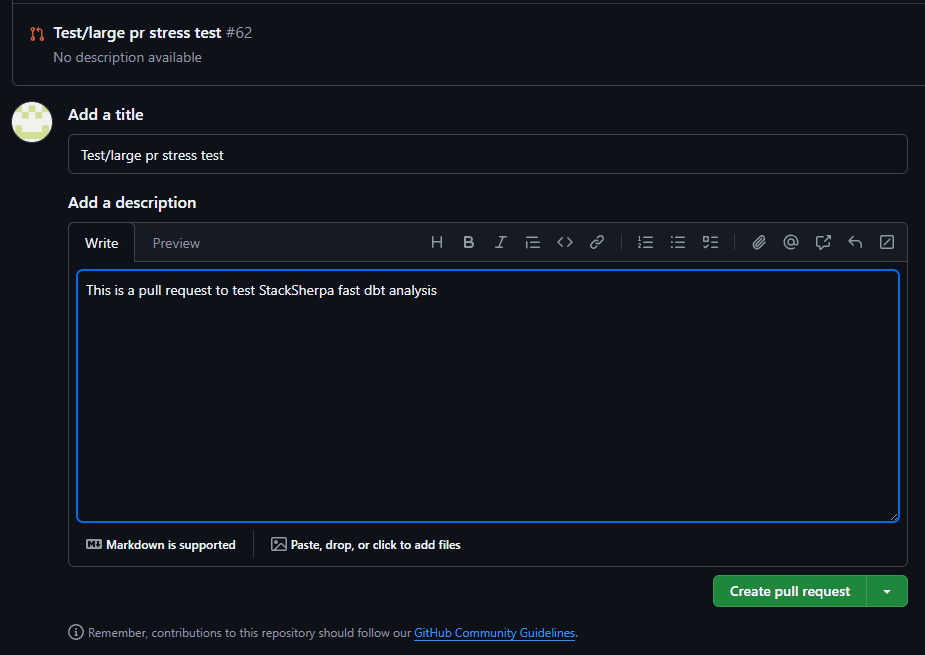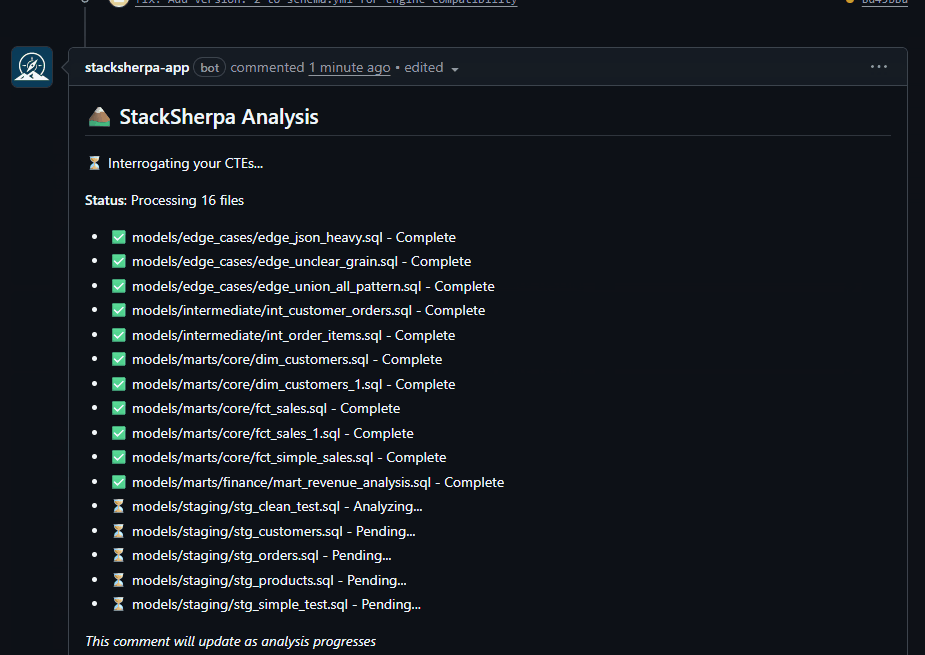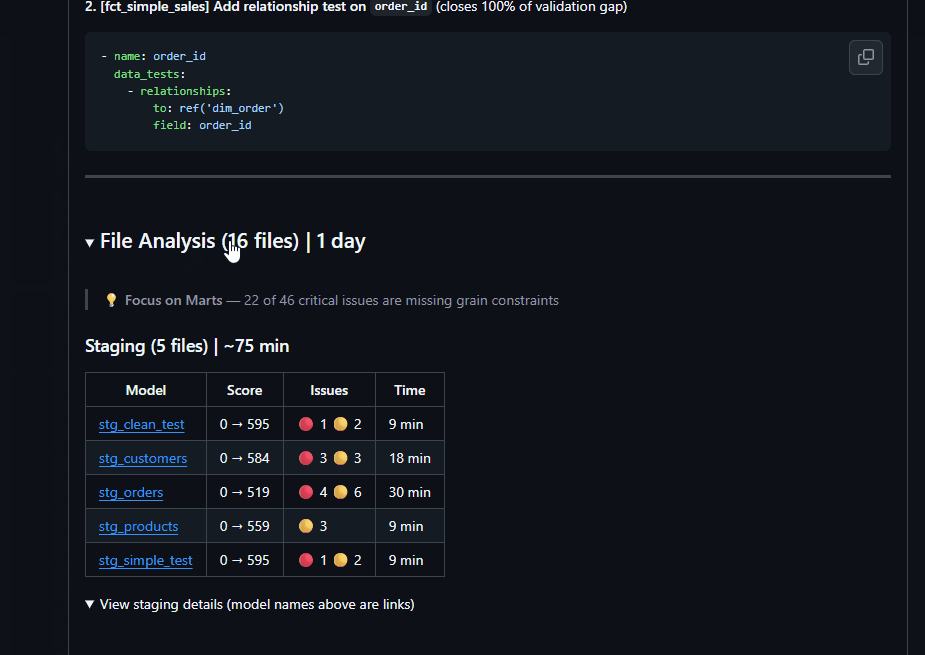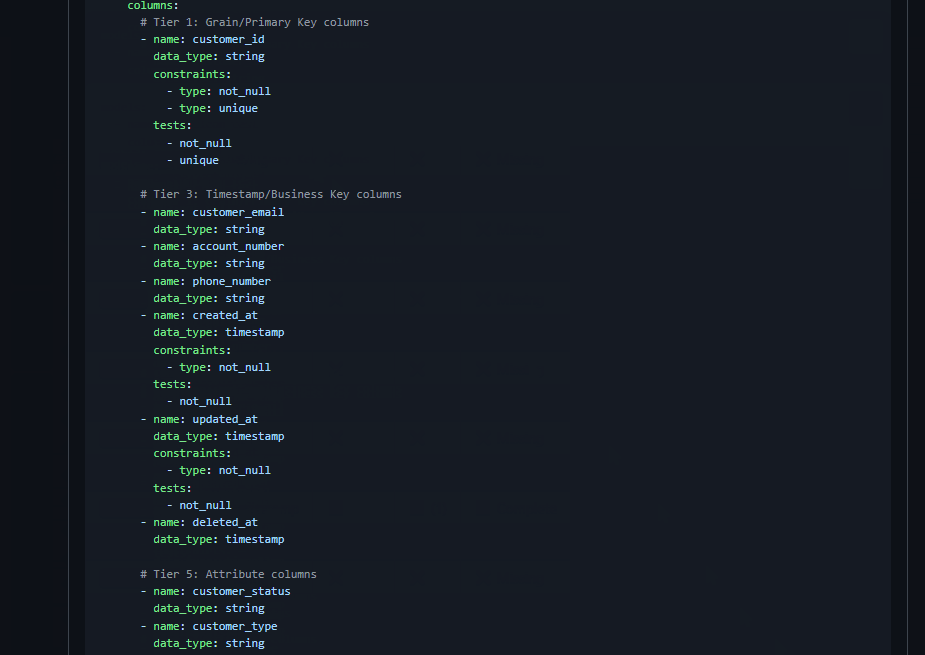
Real analysis of a dbt project. From opening the PR to getting actionable recommendations.
Here's What You Get
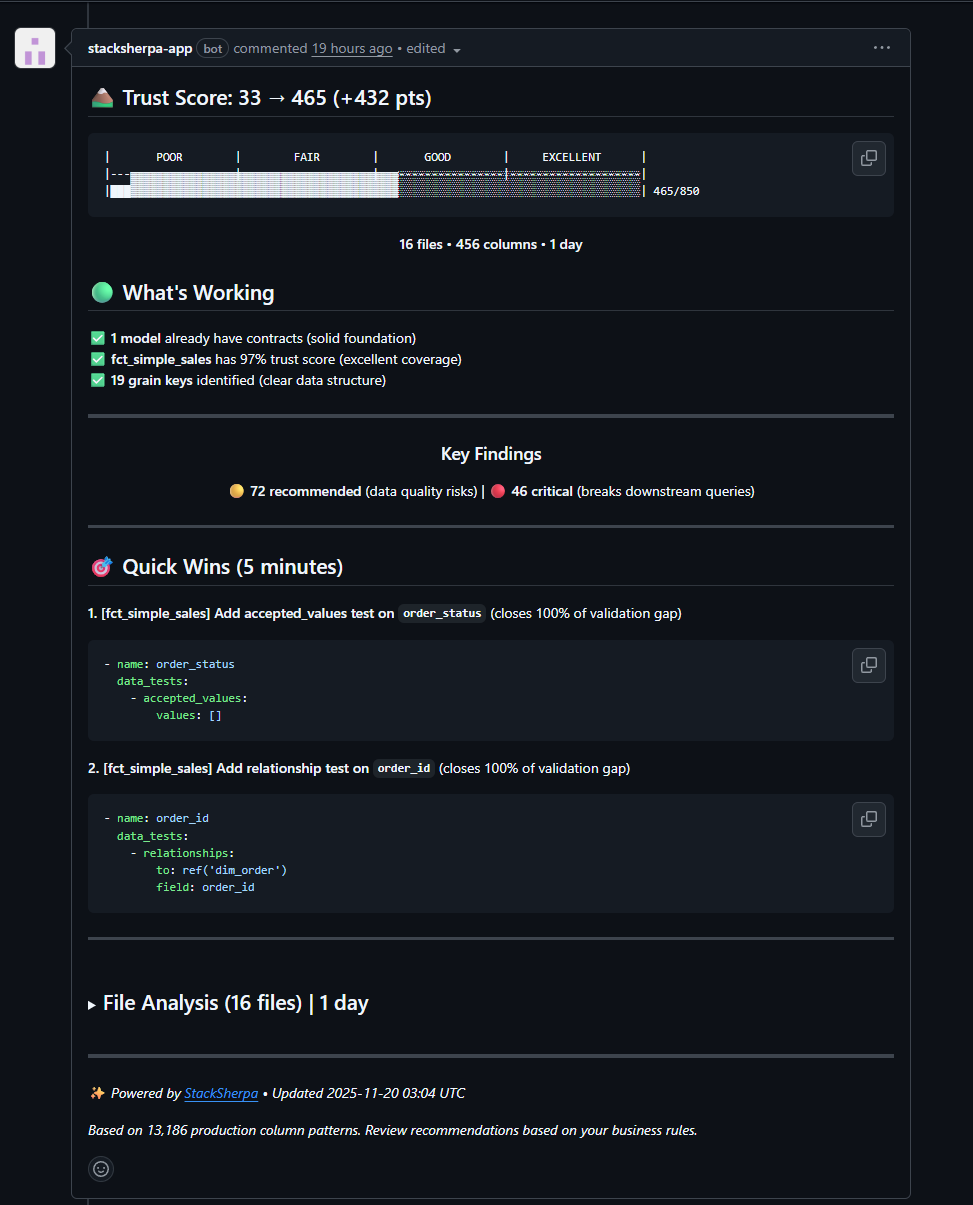
From 33 to 465 in one PR. "What's Working" celebrates your existing tests. "Quick Wins" shows what to add next with copy-paste YAML.
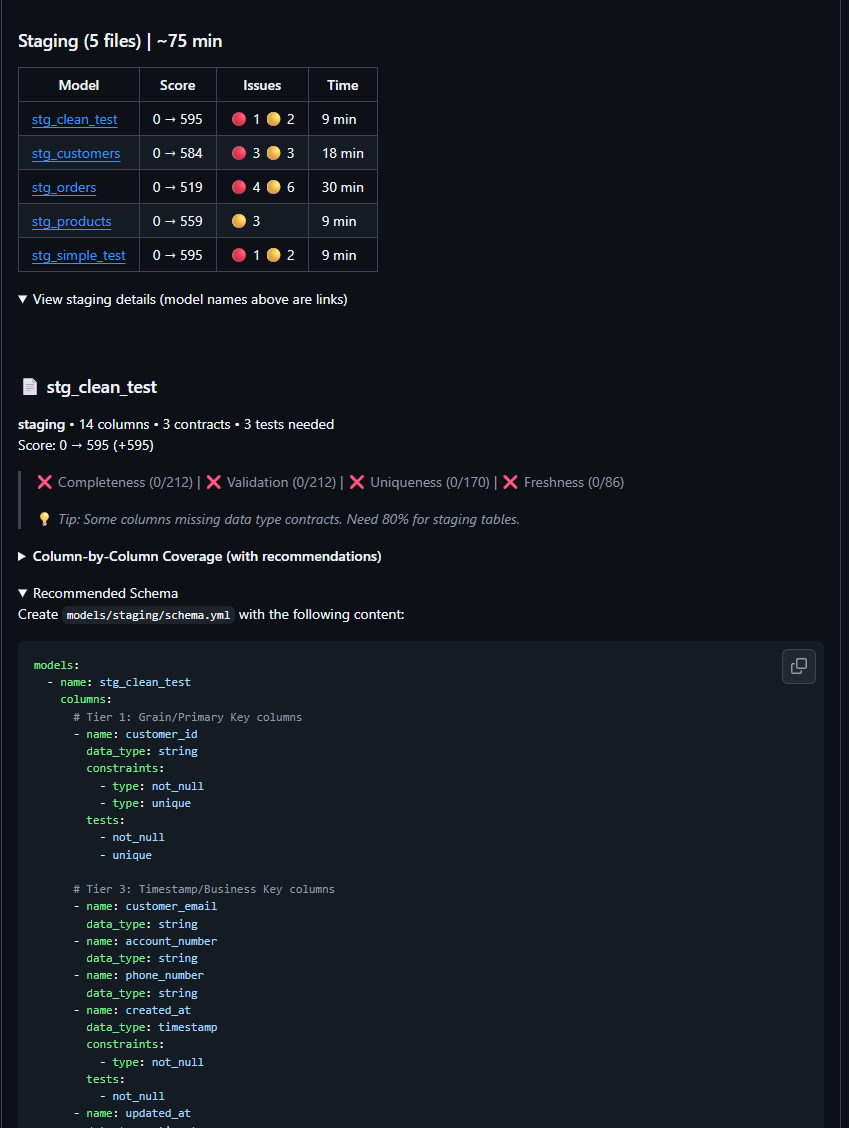
Recommendations organized by tier and data quality framework. Primary keys get unique + not_null. Foreign keys get relationships. Based on 13,186 real dbt columns.
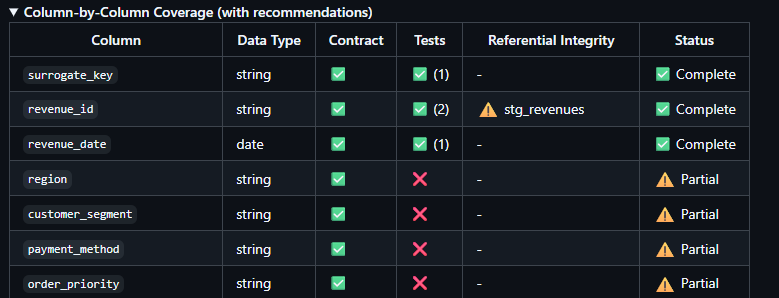
✅ Complete coverage or ⚠️ Partial? You know exactly where you stand. Every column. Every contract. Every test. No surprises.
Watch Your Trust Score Climb
Install in 60 Seconds
One-click GitHub App. Select your repos. Done.
Open Any PR
Work normally. Change models, update schemas, push code.
See Your Score in 10 Seconds
Trust Score (0-850) + exact recommendations to improve it.
Watch It Climb
Add the YAML. Merge. See the score go up next PR.
Make testing part of how your team ships
Frequently Asked Questions
We analyzed thousands of dbt repos (8,355 models, 13,186 unique column names) to build a pattern library. When you write block_timestamp, we know it appears in 611 repos. When you write id, we've seen that pattern 279 times across real projects.
We use pattern matching and semantic analysis, not LLMs that guess. Run the analysis twice? You'll get the exact same recommendations. That's how testing tools should work.
Your Trust Score (0-850) measures how well your dbt project follows data quality best practices. It's based on our progressive testing philosophy: apply the right framework (Completeness, Validation, Uniqueness, Freshness, Consistency) at the right layer (staging → facts → marts) on the right columns (primary keys, foreign keys, measures).
0-200 (Poor) Minimal testing, missing primary key constraints
201-450 (Fair) Basic contracts on key columns, some testing
451-650 (Good) Solid coverage on facts/marts, tier-based testing
651-850 (Excellent) Comprehensive framework coverage, optimized for cost
Higher scores mean better data quality with lower testing costs. We're selective by design. Test what matters, not everything.
No! StackSherpa is actually great for learning. Our recommendations explain WHY things matter and teach best practices. Many users tell us it's helped their junior engineers level up. If you use dbt, StackSherpa will help you write better models.
StackSherpa works with any data warehouse that dbt supports - Snowflake, BigQuery, Redshift, Databricks, Postgres, and more. We analyze your dbt code, not your warehouse directly, so we're warehouse-agnostic.
Most PRs are analyzed in under 10 seconds. Complex PRs with many changed files might take 20-30 seconds. You'll see results posted as a PR comment automatically.
Actually, StackSherpa makes your pipeline faster and more cost-efficient. We're selective by design. Contracts catch schema issues at compile-time (free), and tests only run where data quality needs runtime validation.
Critical customer-facing models get thorough testing. Staging tables get essentials only. Every test recommendation is ranked by impact, so you spend compute credits on what matters, not validation theater.
The result? Faster CI runs, lower warehouse costs, and testing budget directed at business-critical marts instead of staging bloat.
We clone your code temporarily to analyze it, then delete it immediately after analysis. We never store your dbt models or SQL. We only keep metadata (file names, line numbers) to post comments. Your code stays in your GitHub repo.
StackSherpa is currently in a free 90-day beta period. We're focused on gathering feedback and testing product-market fit before finalizing pricing.
Install the GitHub App today and help us shape the future of dbt testing. No credit card required.